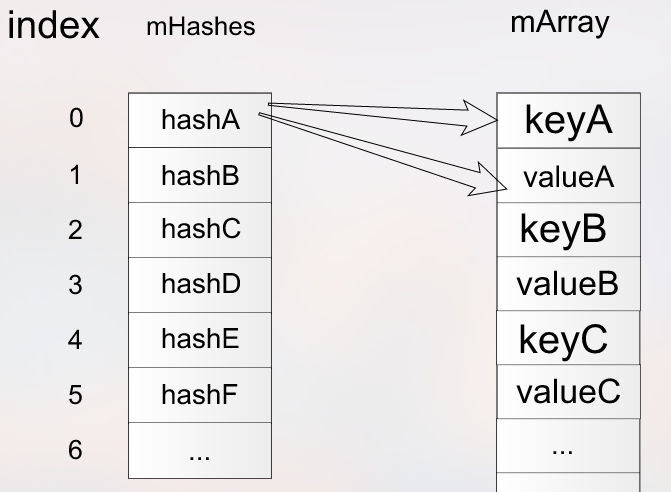
intindexOf(Objectkey,inthash){finalintN=mSize;//快速判断是ArrayMap是否为空,如果符合情况快速跳出if(N==0){return~0;}//二分查找确定索引值intindex=ContainerHelpers.binarySearch(mHashes,N,hash);// 如果未找到,返回一个index值,可能为后续可能的插入数据使用。if(index<0){returnindex;}// 如果确定不仅hashcode相同,也是同一个key,返回找到的索引值。if(key.equals(mArray[index<<1])){returnindex;}// 如果key的hashcode相同,但不是同一对象,从索引之后再次找intend;for(end=index+1;end<N&&mHashes[end]==hash;end++){if(key.equals(mArray[end<<1]))returnend;}// 如果key的hashcode相同,但不是同一对象,从索引之前再次找for(inti=index-1;i>=0&&mHashes[i]==hash;i--){if(key.equals(mArray[i<<1]))returni;}//返回负值,既可以用来表示无法找到匹配的key,也可以用来为后续的插入数据所用。// Key not found -- return negative value indicating where a// new entry for this key should go. We use the end of the// hash chain to reduce the number of array entries that will// need to be copied when inserting.return~end;}
/** * The minimum amount by which the capacity of a ArrayMap will increase. * This is tuned to be relatively space-efficient.*/privatestaticfinalintBASE_SIZE=4;finalintn=mSize>=(BASE_SIZE*2)?(mSize+(mSize>>1)):(mSize>=BASE_SIZE?(BASE_SIZE*2):BASE_SIZE);
privatestaticvoidfreeArrays(finalint[]hashes,finalObject[]array,finalintsize){if(hashes.length==(BASE_SIZE*2)){synchronized(ArrayMap.class){if(mTwiceBaseCacheSize<CACHE_SIZE){array[0]=mTwiceBaseCache;array[1]=hashes;for(inti=(size<<1)-1;i>=2;i--){array[i]=null;}mTwiceBaseCache=array;mTwiceBaseCacheSize++;if(DEBUG)Log.d(TAG,"Storing 2x cache "+array+" now have "+mTwiceBaseCacheSize+" entries");}}}elseif(hashes.length==BASE_SIZE){synchronized(ArrayMap.class){if(mBaseCacheSize<CACHE_SIZE){array[0]=mBaseCache;array[1]=hashes;for(inti=(size<<1)-1;i>=2;i--){array[i]=null;}mBaseCache=array;mBaseCacheSize++;if(DEBUG)Log.d(TAG,"Storing 1x cache "+array+" now have "+mBaseCacheSize+" entries");}}}}
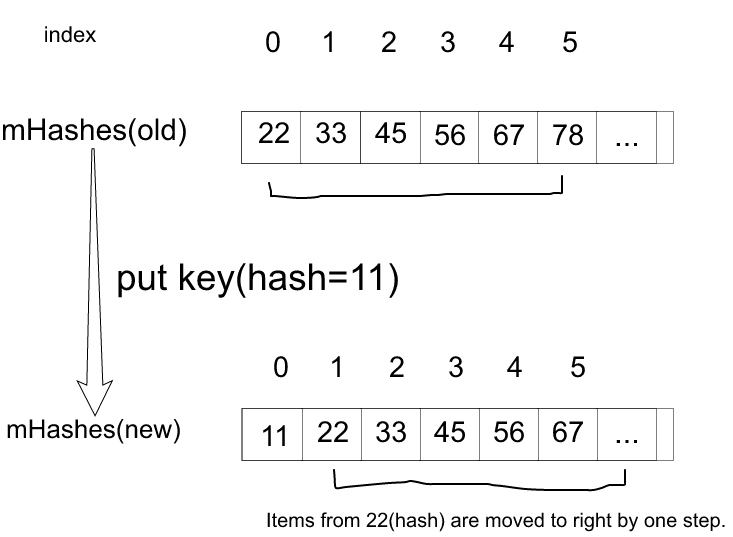
privatevoidallocArrays(finalintsize){if(mHashes==EMPTY_IMMUTABLE_INTS){thrownewUnsupportedOperationException("ArrayMap is immutable");}if(size==(BASE_SIZE*2)){synchronized(ArrayMap.class){if(mTwiceBaseCache!=null){finalObject[]array=mTwiceBaseCache;mArray=array;mTwiceBaseCache=(Object[])array[0];mHashes=(int[])array[1];array[0]=array[1]=null;mTwiceBaseCacheSize--;if(DEBUG)Log.d(TAG,"Retrieving 2x cache "+mHashes+" now have "+mTwiceBaseCacheSize+" entries");return;}}}elseif(size==BASE_SIZE){synchronized(ArrayMap.class){if(mBaseCache!=null){finalObject[]array=mBaseCache;mArray=array;mBaseCache=(Object[])array[0];mHashes=(int[])array[1];array[0]=array[1]=null;mBaseCacheSize--;if(DEBUG)Log.d(TAG,"Retrieving 1x cache "+mHashes+" now have "+mBaseCacheSize+" entries");return;}}}mHashes=newint[size];mArray=newObject[size<<1];}