在Java中,当我们定义一个类的时候,总会出现一些变量是必须要填写的,而另一些是可选的。比如像下面这样,我们定一个Person类,其中name是必须填写的,而性别sex和isChinese可选,如果不填写就直接使用默认值。
1
2
3
4
5
6
| public class Person {
public Person(String name) {}
public Person(String name, int sex) {}
public Person(String name, boolean isChinese){}
public Person(String name, int sex, boolean isChinese) {}
}
|
当仅仅只有这两个可选参数时,上述的情况还好很多,可是当新增了其他的属性的时候,我们需要实现更多的构造方法重载。这在Java中更加容易出现telescoping constructor的问题,进而影响我们的开发效率和代码可读性。
在Kotlin中,这种问题得到了很好的解决。这便是要提到的方法的默认参数,其实这个很简单,在其他的语言也是支持的。
便于大家理解,我们先看一看默认参数是什么,下面是一个Book的类和它的构造方法(Kotlin代码)
1
2
3
| class Book(var name: String, val isChineseBook: Boolean = true,
val hasMultipleAuthor: Boolean = false, val isPopular: Boolean = false,
val isForChildren: Boolean = false) {
|
我们在调用的时候可以按照如下的Kotlin代码
1
2
3
4
5
6
| 1 Book("Book0")
2 Book("Book1", isForChildren = false)
3 Book("Book2", true)
4 Book("Book3", true, true)
5 Book("Book4", true, true, true)
6 Book("Book5", true, true, true, true)
|
我们可以根据自己的需要填写必要的参数值,当然也可以像第1行Book("Book1", isForChildren = false) 不按照顺序填写参数也是可以的,这是一个很赞的特性,能很大程度上增强代码的可读性。
但是Kotlin的这一特性,只应用于Kotlin代码调用的场景,如果是在Java代码中,我们还是必须要填写完整的参数。这一点着实令人沮丧。不过还在有一个解决办法,那就是使用@JvmOverloads注解,示例如下
1
| class People @JvmOverloads constructor(val name: String, val sex: Int = 1, val isChinese: Boolean = true)
|
在Java中调用示例效果
1
2
3
4
| //call constructor with JVMOverloads
People people = new People("");
People people1 = new People("", 0);
People people2 = new People("", 1, true);
|
那么JvmOverloads是如何工作的呢?
其实@JvmOverloads的作用就是告诉编译器,自动生成多个该方法的重载。因为我们通过反编译分析即可验证
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| @JvmOverloads
public People(@NotNull String name, int sex, boolean isChinese) {
Intrinsics.checkParameterIsNotNull(name, "name");
super();
this.name = name;
this.sex = sex;
this.isChinese = isChinese;
}
// $FF: synthetic method
@JvmOverloads
public People(String var1, int var2, boolean var3, int var4, DefaultConstructorMarker var5) {
if((var4 & 2) != 0) {
var2 = 1;
}
if((var4 & 4) != 0) {
var3 = true;
}
this(var1, var2, var3);
}
@JvmOverloads
public People(@NotNull String name, int sex) {
this(name, sex, false, 4, (DefaultConstructorMarker)null);
}
@JvmOverloads
public People(@NotNull String name) {
this(name, 0, false, 6, (DefaultConstructorMarker)null);
}
|
注意,上面的重载方法并没有按照组合来生成,比如public People(@NotNull String name, int sex, boolean isChinese),因为这样也是出于可读性来考虑和避免潜在方法签名冲突问题。
最后,我们来研究一下Kotlin中默认参数的实现原理。因为这里面存在着一些程序设计的巧妙之处。
这里我们还是使用刚刚提到的Book这个类
1
2
3
4
| class Book(var name: String, val isChineseBook: Boolean = true,
val hasMultipleAuthor: Boolean = false, val isPopular: Boolean = false,
val isForChildren: Boolean = false) {
}
|
通过反编译,我们得到了一些类似这样的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| public Book(@NotNull String name, boolean isChineseBook, boolean hasMultipleAuthor, boolean isPopular, boolean isForChildren) {
Intrinsics.checkParameterIsNotNull(name, "name");
super();
this.name = name;
this.isChineseBook = isChineseBook;
this.hasMultipleAuthor = hasMultipleAuthor;
this.isPopular = isPopular;
this.isForChildren = isForChildren;
}
// $FF: synthetic method
public Book(String var1, boolean var2, boolean var3, boolean var4, boolean var5, int var6, DefaultConstructorMarker var7) {
if((var6 & 2) != 0) {
var2 = true;
}
if((var6 & 4) != 0) {
var3 = false;
}
if((var6 & 8) != 0) {
var4 = false;
}
if((var6 & 16) != 0) {
var5 = false;
}
this(var1, var2, var3, var4, var5);
}
|
是不是有点不一样,它只生成了两个构造方法,而不是所谓的多个参数组合的构造方法。更有意思的是,当我们这样调用时
1
2
3
4
5
| Book("Book0")
Book("Book2", true)
Book("Book3", true, true)
Book("Book4", true, true, true)
Book("Book5", true, true, true, true)
|
其对应的字节码反编译成java是
1
2
3
4
5
| new Book("Book0", false, false, false, false, 30, (DefaultConstructorMarker)null);
new Book("Book2", true, false, false, false, 28, (DefaultConstructorMarker)null);
new Book("Book3", true, true, false, false, 24, (DefaultConstructorMarker)null);
new Book("Book4", true, true, true, false, 16, (DefaultConstructorMarker)null);
new Book("Book5", true, true, true, true);
|
我们会注意到上面有很多数字,比如30,14,28,24,16等。那么这些数字是怎么生成的呢?
对于构造方法的每个参数,
- 都有一个位置,即方法声明时所在的位置,我们这里使用i代替表示。注意该从0开始,
- 每个参数有一个mask值,该值为2的i次方,比如第0个位置的参数的mask值为1,第1个位置的mask值为2,以此类推。
- 如果在调用时,编译器检测到某些参数没有调用,就将这些参数的mask值,求和,便生成了我们上面提到的数字。
具体示例如下
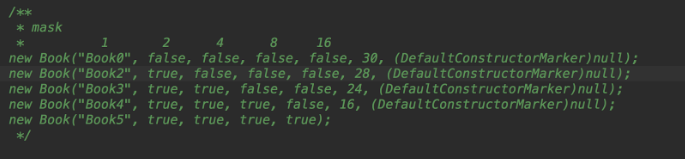
比如Book(“Book0”)我们传递了第一个参数,所以最后的30 就是由 2 + 4 + 8 + 16 这些缺失的位置的mask值计算得出来的。
知道了,mask值的生成规则,就便于我们理解编译器生成的构造方法了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| // $FF: synthetic method
public Book(String var1, boolean var2, boolean var3, boolean var4, boolean var5, int var6, DefaultConstructorMarker var7) {
if((var6 & 2) != 0) {
var2 = true;
}
if((var6 & 4) != 0) {
var3 = false;
}
if((var6 & 8) != 0) {
var4 = false;
}
if((var6 & 16) != 0) {
var5 = false;
}
this(var1, var2, var3, var4, var5);
}
|
其实这个构造方法就是根据根据mask判断,某个位置的参数是否在调用时进行了赋值,如果没有赋值则进行设置默认值操作。
这种使用mask或者flag的方法其实很巧,减少了一些不必要的重载方法的生成。对于我们以后处理类似的问题,提供了一些不过的思路和参考价值。

